Honey, I shrunk the circuits!
contents
Compressing model capabilities by making their circuits extractable.
By Abhishek Mishra and Krishna Pagare

Abstract
A model can know how to do something without exposing the part of itself that does it. Dense language models often carry capabilities as distributed structure: usable at the surface, but not local enough to isolate, route, update, or remove. Fixed-model interpretability can identify components that matter for a behavior. The harder object is a capability that can be recovered and tested as a small causal substrate.
We introduce low-rank circuit conditioning, a constrained adapter update that preserves the model's output behavior while reshaping how an existing capability is represented. In the base model, standard compact recovery stalls at 29%. After conditioning, the same extraction pipeline reaches 91.33% autoregressive full-answer recovery from 5.05% of MLP channels. The evidence points to concentration of task-relevant activity inside recoverable channels, not global rank collapse.
The missing object
Several existing tools can steer a model from the outside. Prompts and activation steering methods change behavior at inference time (Turner et al., 2023; Zou et al., 2023). Adapters, LoRA updates, and task vectors move the model along learned behavioral directions (Hu et al., 2021; Ilharco et al., 2023). Sparse features make parts of the representation easier to inspect (Cunningham et al., 2024).
Those tools are useful, but they do not give us the object we want. A prompt can make the model add, but it does not identify the machinery that adds. A fine-tune can teach a format, but it does not isolate the format-following substrate. A refusal behavior can be induced without giving us the part we could detach and audit.
What we want is stricter: a task-level circuit handle, meaning a small causal substrate inside the model that carries a whole capability under intervention.
Prior work makes this target plausible but does not solve this version of it. García-Carrasco et al. (2025) prune fixed models into task-specific circuits for faster inference. Gao et al. (2025) show that weight-sparse transformers can expose readable circuits for simple behaviors. Arora et al. (2026) show that dense-model MLP activations can support sparse, faithful circuit tracing in the neuron basis.
Our contribution starts from the gap those results leave open. We condition a dense model so a capability that was diffuse under standard extraction becomes recoverable as a compact causal mask. The question is not whether circuits exist somewhere in the model. It is whether we can make a capable model expose the circuit for a behavior we care about.
The direction is model compression through circuit extractability. If a conditioned model can expose compact causal masks for existing capabilities, those masks become candidates for routing, auditing, updating, or removal. This post tests the first step: can conditioning move a known capability from diffuse recovery to compact recovery?
The extraction wall
If a capability lives in a dense model as a diffuse pattern of activations and weights, then the question of location is underspecified. A feature can fire during the behavior. A head can matter when ablated. A layer can show a peak in attribution. Those are useful clues, but they are not the capability. We want a causal substrate: the part we can keep under intervention while the behavior remains.
Task as audit surface
We chose the task before we chose the method, because the task determines what counts as evidence. We needed a behavior with four properties:
- Exact labels. The question "did the circuit produce the behavior?" has to have a yes-or-no answer rather than a judgment call.
- Exhaustive input space. We have to be able to enumerate or cleanly sample the full distribution of inputs, so we cannot fool ourselves with a lucky test set.
- Stratifiable internal structure. The behavior has to decompose into sub-decisions that can be examined independently. Otherwise failure is opaque.
- Multi-token autoregressive output. A circuit that survives one-token classification is not the same object as a circuit that survives generating a full answer where each token conditions the next.
Two-sum integer addition satisfies all four. It can scale from small bounded ranges to much longer digit strings while preserving the same scientific structure. Every answer is exact, the input space can be enumerated or cleanly sampled, the computation has separable internal regimes, and the output must be generated token by token. We use a bounded two-number setting because it gives us the strongest possible audit surface: small enough to check exhaustively, rich enough to expose carries, digit-position dependencies, result-length changes, and overflow regimes.
The current experiments use Qwen/Qwen2.5-Math-1.5B (Yang et al., 2024), which reaches 94.86% exact accuracy on the exhaustive two-digit addition audit before conditioning. Earlier Qwen3-1.7B runs (Yang et al., 2025) set up the problem but are not the main result. High base accuracy makes the localization question clean. If the model were weak at addition, a failed sparse mask could mean the behavior was diffuse or that the behavior was never reliable enough to localize. The attribution pass therefore focuses on correct examples, where the behavior is actually being executed.
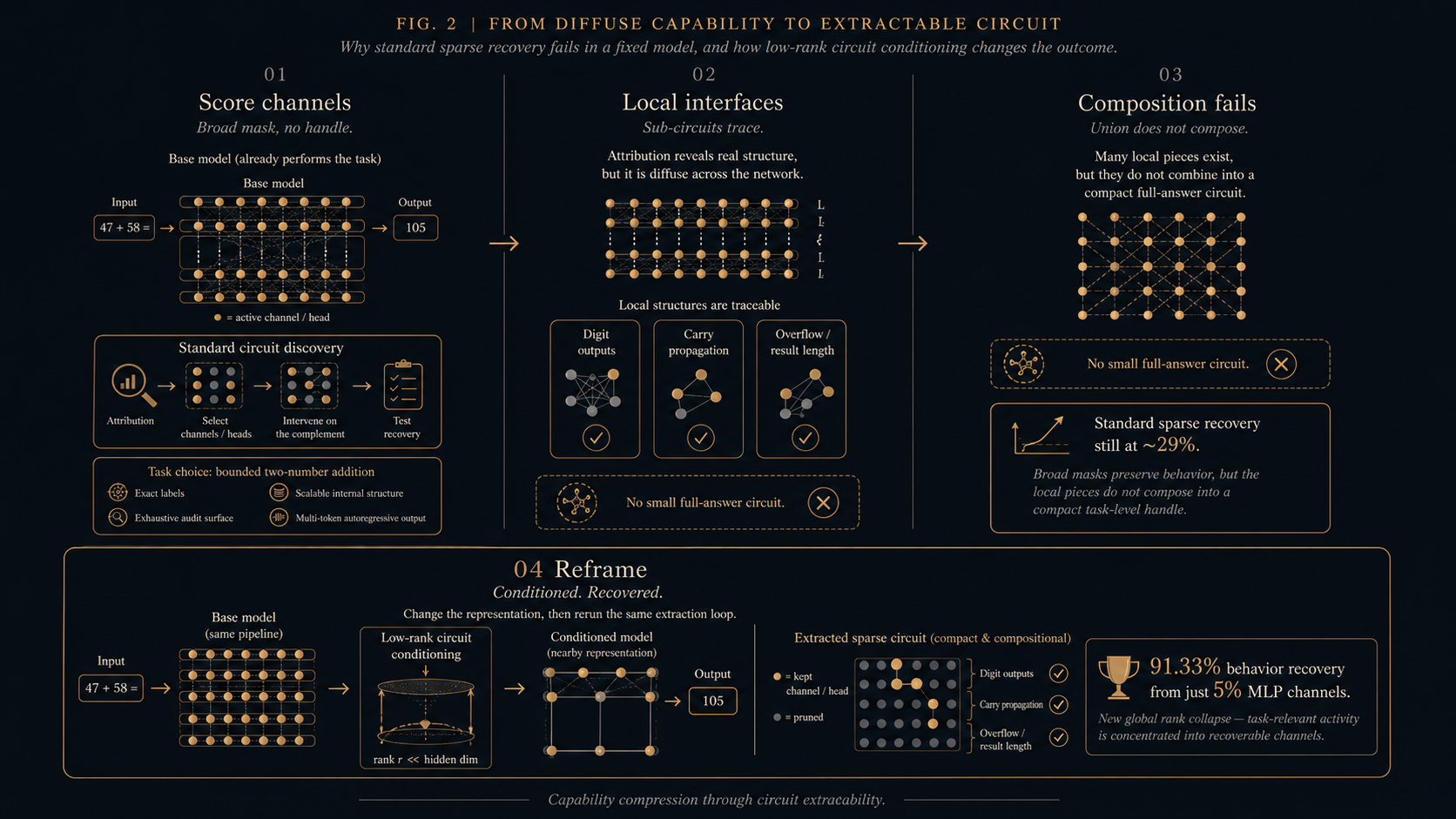
Fig. 2. Methodology overview. The behavior stays fixed while the searched representation changes. The base pass applies attribution, mask selection, and causal recovery to the original model. Local-interface analysis finds compact pieces that do not compose. The conditioned pass applies a constrained low-rank update, then reruns the same recovery test to ask whether the existing capability becomes extractable.
The standard loop finds signal, not a circuit
The first pass uses the standard post-hoc discovery loop. Attribution scores MLP channels on examples where the model produces the right answer. Those scores are aggregated across examples into candidate masks, then tested causally by intervening on everything outside the mask. A channel is evidence only when the constrained model still produces the behavior. This score-then-test structure underlies ACDC (Conmy et al., 2023), edge attribution patching (Syed et al., 2023), and neuron-basis tracing in Arora et al. (2026).

Fig. 3. Attribution proposes a mask; intervention tests it. A high-scoring channel may be part of the computation, or it may sit downstream of the computation and inherit its signal. The score alone cannot separate those cases.
The acceptance rule is causal recovery. We keep the candidate mask, intervene on the rest of the model, and measure exact task accuracy. High attribution without recovery remains a correlation. Recovery under intervention is the evidence that the mask carries the behavior.
Throughout this section, recovery means exact task accuracy after intervention. For full addition, recovery is exact full-answer accuracy, reported separately under teacher-forced and autoregressive evaluation. Table 1 uses full-answer counterfactual patching: selected MLP channels receive the target example, while the complement receives matched counterfactual activations. The appendix records the intervention conventions.
Counterfactual patching. The kept channels receive activations from the target example, while the rest of the model receives activations from a matched alternative example. This tests whether the kept channels preserve the target behavior under a structured intervention. The replacement activations are not blank, so they can still carry task information.
Table 1. An MLP channel here means one intermediate MLP neuron in one layer. The main model has 28 layers with 8,960 MLP channels each, so the MLP channel universe is 250,880 channels. Conditioning moves the full-addition recovery frontier. The task and recovery test are fixed across rows: exact full-answer accuracy under counterfactual patching on 1,500 matched records. In the base representation, compact masks stall while near-complete recovery requires most MLP channels. After rank-32 KL conditioning, the same extraction loop recovers high full-answer accuracy from about five percent of MLP channels.
| Setting | MLPs | MLP share | Recovery | Procedure / interpretation |
|---|---|---|---|---|
| Base compact mask | 14,436 | 5.75% | 29.00% | Direct compact composed mask; comparable compact pre-conditioning point. |
| Base broad recovery mask | 227,320 | 90.61% | 99.53% | High recovery returns only when almost the whole MLP universe is kept. |
| Conditioned MVC, rank-32 KL | 11,672 | 4.65% | 90.60% TF / 90.60% AR | Later compression of the conditioned mask; smallest target-90 point found. |
| Conditioned direct mask, rank-32 KL | 12,661 | 5.05% | 91.87% TF / 91.33% AR | Direct rerun of the standard extraction loop on the conditioned model. |
As the mask shrinks, recovery collapses. The best compact full-task mask in the base representation recovers only 29%. High recovery returns only when the mask becomes too broad to function as a circuit handle.
Large masks recover addition because attribution tracks real arithmetic signal. Compact masks test the stronger claim: whether that signal can act as a sparse causal substrate. In the base model, it cannot.
Counterfactual patching made some candidate masks look smaller, but we treat those runs as diagnostic rather than decisive. Later controls showed that counterfactual and mean replacements can carry task-shaped information through the complement. The headline comparisons therefore keep intervention conventions explicit and reserve leakage-sensitive details for the appendix.
The pieces are local
When full-task masks fail, the next question is whether the model carries compact pieces of the computation. Addition has natural sub-decisions: per-digit outputs, carry propagation, result-length transitions, and overflow regimes. Each is smaller than the full answer, and each can be tested with the same attribution-and-intervention loop applied to its own causally defined sub-problem.
The construction of these interfaces matters. We compare examples that are already correct and matched on everything except the local decision under study: result length, prompt-token length, and the other answer digits stay fixed. That makes the attribution question much cleaner than asking why one full answer succeeded and another failed.
Several interfaces survive this local test. The clearest is overflow: under counterfactual intervention, a small fraction of MLP channels can recover that local decision. That result rules out the trivial explanation that attribution cannot find arithmetic structure at all. It can find causal pieces. The failure is at the task level, not at every local interface.
The locality is also uneven. Carry and overflow interfaces are the clearest compact wins, while ordinary digit-value decisions remain much more spread out. So the evidence is not that arithmetic is locally stored everywhere. It is that some causal sub-decisions expose clean handles while the full behavior does not.
The pieces do not assemble
The local-interface pass leaves a plausible bet. If digit, carry, result-length, and overflow masks are real pieces of addition, then a union of those masks, or a route through them during generation, should recover the full behavior at compact scale.
That test fails. The union does not recover full addition compactly, and routed composition only works after the mask grows too large to be a useful circuit handle.
We then tested the main technical alternatives. Teacher-forced prefixes clean up earlier answer tokens. Sequential interface tracing applies each mask at the generation step where its sub-decision is made. Carry and result-length stratification separate regimes that might otherwise interfere. Conflict pruning removes channels that help one sub-problem but hurt another. Adaptive split search and causal group ranking test whether the failure is driven by pairing, thresholding, or sample count.
Those repairs improve diagnostics, not the full-task frontier. The local masks become cleaner and some sub-decisions sharpen, but the composed behavior still fails at compact scale. The base representation exposes pieces of addition without exposing the binding computation that makes them a task-level circuit.
Reshaping the representation
Section 2 leaves a specific failure. The base model exposes local arithmetic structure, and the discovery loop can find it. What it does not expose is a compact full-task mask in the model's native coordinates.
That failure shifts the hypothesis. The search procedure may be adequate for local pieces while the representation is poorly aligned with the full behavior. In that case, searching harder maps the diffusion; it does not create a sparse handle.
The basis as the hidden assumption
Post-hoc circuit discovery usually keeps the model fixed. It asks whether the behavior is already exposed in the current basis of channels, heads, and activations. The procedure can look neutral because it only scores, ranks, masks, and tests components.
The basis assumption matters because fluent addition is not the same as addition stored in a small set of channels. Transformer-circuits and superposition work make the same point from the opposite direction: a model can implement crisp behaviors while their internal features are distributed across many directions (Elhage et al., 2021; Elhage et al., 2022). If the model spreads the computation across many directions, attribution can describe that spread without turning it into a compact causal mask.
Conditioning without teaching
High base accuracy gives us the premise for conditioning. The model already performs addition, so the intervention does not need to teach the task from scratch. It only needs to change how the existing behavior is represented.
The wall in Section 2 suggests structure in the wrong basis: enough arithmetic structure for attribution to trace pieces, not enough alignment for a sparse channel mask to carry the full behavior.
We attach a low-rank adapter (Hu et al., 2021; Kalajdzievski, 2023) and train it on the same addition behavior, but the adapter is not free to become an arbitrary new solver. A KL term keeps the conditioned model close to the base model's output distribution, echoing the soft-target anchoring used in knowledge distillation (Hinton et al., 2015). The task loss keeps the behavior active; the KL loss keeps the move anchored to the original model.
We keep the comparison fixed. Conditioning changes the representation; the task, attribution family, mask-selection loop, and recovery test stay the same. The held-out recovery records are separate from the adapter update.
Algorithmically, the method has six steps:
- Freeze the base model.
- Train a low-rank adapter on addition with task loss plus KL to the base distribution.
- Sweep adapter merge scales.
- Keep only scales that preserve the task-accuracy target.
- Merge the lowest-KL surviving scale into the base weights.
- Rerun the original attribution, mask-selection, and causal-recovery loop.
The merge is ordinary LoRA weight merging (Hu et al., 2021); the special choice is the conservative scale. We use the lowest-drift scale that still preserves the behavior, so the adaptation acts as a small representational move rather than a free new solver.
Representation conditioning differs from ordinary fine-tuning. Fine-tuning asks whether a model can learn or improve a behavior. Here the behavior is already present at high accuracy. The experiment asks whether a constrained nearby model can make that existing behavior recoverable by the same extraction loop.
Minimal viable circuit
Before conditioning, high recovery required keeping 90.61% of MLP channels active. The intervention itself can preserve addition when enough of the model remains, so the failure is not a broken recovery test. The base representation fails specifically at compact causal recovery.
The conditioned rows move the frontier. Direct extraction gives 91.87% teacher-forced and 91.33% autoregressive recovery from 12,661 MLP channels. Compressing that mask gives the 11,672-channel MVC at 90.60% recovery. The appendix keeps artifact provenance and exploratory variants separate from this main comparison.
The 12,661-channel mask is representation-conditioned and it recovers 91.33% autoregressive full-answer behavior on the model, but fails on the base and no-KL variants. The base model already has the behavior, but conditioning does not merely reveal an old mask. It changes the representation so a compact mask becomes causally sufficient under the same recovery test.

Fig. 4. KL-regularized conditioning moves the sparse-recovery frontier. Orange points trace rank-32 KL masks under full-answer generation, with the smallest 90% mask at 11,672 MLP channels, or 4.65% of the MLP universe. Gray controls and baselines either fail at comparable compact scale or need roughly 170,000 to 180,000 channels to reach 90%, separating compact causal recovery from ordinary task training or broad recovery.
Ablations
This section records the ablations we ran to understand what helps, and which apparent signals might be weak or misleading. Each control run changes the training or conditioning path, then reruns the same sparse full-addition recovery test.
Ordinary task training improves behavior in some branches, and broad masks can still recover the task. However neither result gives a compact circuit handle. For this two-sum addition task, compact recovery only appears when the update is low-rank, KL-anchored, and large enough to move the representation.
Table 2. Among the tested variants, compact recovery appears only under rank-32 KL conditioning. Each row keeps the sparse full-addition recovery test fixed unless noted.
| Variant | Training change | Compact recovery | Implication |
|---|---|---|---|
| Rank-32 KL LoRA | Low-rank adapter with task loss plus KL to the base distribution; lowest-drift merge scale that preserved accuracy. | 12,661 MLPs reach 91.33% AR; the squeezed 11,672-channel mask reaches 90.60%. | Only tested variants above 90% recovery at compact scale. |
| Rank-32 no-KL LoRA | Same rank, data, and adapter family, but no KL anchor. | 49.53% at a similar compact scale; about 167,065 MLPs needed for 90%. | Task training alone does not make the behavior compact. |
| Lower-rank KL LoRA | Same KL objective with smaller adapter ranks. | The best lower-rank target run needs about 170,259 MLPs for 90.47%. | The KL anchor needs enough rank to reshape the representation. |
| Full-parameter SFT | All weights allowed to train. | About 179,311 MLPs needed for 90.80%. | More trainable capacity does not imply extractability. |
| Wrong-task and format controls | Format-only, copy, digit reversal, random labels, and next-token KL-only controls. | No sparse arithmetic mask; KL-only compact mask reached 11.40%. | The effect is task-specific, not generic KL or formatting. |
| Behavioral SFT side branch | SFT on 3-digit failure pairs. | Behavior improves and generalizes, but this does not establish compact circuit recovery. | Accuracy gain is not the same claim as compact circuit recovery. |
| Non-math replication and extra supervision | Same recipe on non-math Qwen2.5-1.5B, then a variant with extra supervised data. | Non-math KL needs 114,026 for 90.07%; no-KL needs 157,696 for 89.67%; extra-supervision KL reaches 88.47% at 23,813. | Pretraining and supervision shape how much conditioning can compact the frontier. |
The rank sweep ablations suggest that a Goldilocks regime exists for low-rank conditioning. Lower-rank KL updates leave the representation too hard to move. Full-parameter SFT and no-KL training give the optimizer more freedom, but do not make the recovered substrate compact. Rank-32 KL conditioning sits between those failures with enough freedom to move the arithmetic representation, and enough constraint to preserve the recovery test.
Effective rank (Roy and Vetterli, 2007) does not collapse after conditioning; mean effective rank is higher under rank-32 KL than in the base model. Task activity instead concentrates inside the recovered mask. Mask-energy share rises from 0.329 to 0.462, and the sparse mask becomes causally sufficient for most full answers. The supported claim in this research is that constrained low-rank conditioning can make an existing dense-model capability recoverable as a compact causal mask.
Conclusion and further work
The current evidence supports five claims:
- A model can perform a behavior fluently while failing to expose a compact task-level circuit in its native basis.
- Local arithmetic interfaces can be recovered without composing into a full-behavior handle.
- Changing the representation under a KL constraint can move the sparse recovery frontier without changing the task or the extraction loop.
- In these runs, the effect is not explained by ordinary LoRA, full-parameter SFT, mask size, or generic KL training.
- The recovered object is a causal substrate inside the model, not yet a standalone compressed model.
The research direction is model compression through circuit extractability. The current result is narrower than whole-model compression: conditioning makes a capability visible to compression machinery that could not see it before. The next target is the higher-value operation: get a capability handle, then extract, update, or reuse it.
References
- Arora, A., Wu, Z., Steinhardt, J., and Schwettmann, S. (2026). Language model circuits are sparse in the neuron basis. arXiv preprint arXiv:2601.22594.
- Chughtai, B., Chan, L., and Nanda, N. (2023). A toy model of universality: Reverse engineering how networks learn group operations. Proceedings of the 40th International Conference on Machine Learning, PMLR 202:6243-6267.
- Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. (2023). Towards automated circuit discovery for mechanistic interpretability. Advances in Neural Information Processing Systems 36.
- Cunningham, H., Ewart, A., Riggs Smith, L., Huben, R., and Sharkey, L. (2024). Sparse autoencoders find highly interpretable features in language models. International Conference on Learning Representations.
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., et al. (2021). A mathematical framework for transformer circuits. Transformer Circuits Thread.
- Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., et al. (2022). Toy models of superposition. arXiv preprint arXiv:2209.10652.
- Frankle, J., and Carbin, M. (2019). The lottery ticket hypothesis: Finding sparse, trainable neural networks. International Conference on Learning Representations.
- Gao, L., Rajaram, A., Coxon, J., Govande, S. V., Baker, B., and Mossing, D. (2025). Weight-sparse transformers have interpretable circuits. arXiv preprint arXiv:2511.13653.
- García-Carrasco, J., Maté, A., and Trujillo, J. (2025). Extracting interpretable task-specific circuits from large language models for faster inference. Proceedings of the AAAI Conference on Artificial Intelligence, 39(16), 16772-16780.
- Han, S., Mao, H., and Dally, W. J. (2016). Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. International Conference on Learning Representations.
- Hinton, G., Vinyals, O., and Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. (2021). LoRA: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. (2023). Editing models with task arithmetic. International Conference on Learning Representations.
- Kalajdzievski, D. (2023). A rank stabilization scaling factor for fine-tuning with LoRA. arXiv preprint arXiv:2312.03732.
- Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. (2019). Similarity of neural network representations revisited. International Conference on Machine Learning.
- Louizos, C., Welling, M., and Kingma, D. P. (2018). Learning sparse neural networks through L0 regularization. International Conference on Learning Representations.
- Meng, K., Bau, D., Andonian, A., and Belinkov, Y. (2022). Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems 35.
- Nanda, N., Chan, L., Lieberum, T., Smith, J., and Steinhardt, J. (2023). Progress measures for grokking via mechanistic interpretability. International Conference on Learning Representations.
- Roy, O., and Vetterli, M. (2007). The effective rank: A measure of effective dimensionality. Proceedings of the European Signal Processing Conference.
- Syed, A., Rager, C., and Conmy, A. (2023). Attribution patching outperforms automated circuit discovery. NeurIPS ATTRIB Workshop. arXiv:2310.10348.
- Turner, A. M., Thiergart, L., Udell, D., Leech, G., Mini, U., and MacDiarmid, M. (2023). Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248.
- Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., et al. (2024). Qwen2.5-Math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122.
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
- Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., et al. (2023). Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405.
Appendix: Experiment chronology
This appendix records the experimental path behind the main claim. It is chronological because the order matters. Each stage closed off a simpler explanation and forced the next question: can attribution find a signal, can that signal become compact, does decomposition help, does the model matter, and does the basis matter?
Setup: A task that could make us wrong
The task choice set the evidential standard. Two-sum integer addition gave exact labels, an enumerable bounded input space, separable digit and carry regimes, and multi-token autoregressive outputs. The early runs used Qwen3-1.7B, while the main extraction result uses Qwen2.5-Math-1.5B. Both already performed the bounded task well enough for localization to mean something. The math model reaches 94.86% exhaustive two-digit accuracy before conditioning, so a failed mask cannot be dismissed as a weak base behavior.
Exp 1: Signal without a handle
The first question was whether top-k attribution found anything real. The answer was yes, but only at a scale too large to be useful. In the early Qwen3-1.7B runs, the full model baseline was 95%, and the smallest mask above the 80% recovery threshold still needed 59,136 channels. A firing-frequency scan also found recurring channels, including L27 N3227 firing on every correct example in the scanned set. The signal was not random, but the object was too large. The question shifted from whether attribution could find arithmetic signal to whether that signal could become a usable circuit handle.
Exp 2: Intervention shape became part of the evidence
The next pass separated candidate sparsity from causal recovery. Simple activation thresholding showed an asymmetry: almost every MLP channel appeared at a positive threshold, but stricter relative thresholds sharply reduced the MLP set while attention stayed broadly engaged. That made MLPs the natural search surface, but still only as candidates.
Counterfactual patching changed the intervention. The kept subset received the real input, while the complement received a matched counterfactual example. This made smaller masks look behavior-carrying: k=20,000 reached 95% accuracy under counterfactual patching, compared with roughly k=50,000 without it. The result was useful, not decisive. The complement can leak task-shaped information, so counterfactual patching became a diagnostic probe rather than the final standard for isolation.
Exp 3: Decomposition found pieces, then hit the wall
Switching to a math-tuned model helped, but not enough. The first compact result came from decomposing addition into local interfaces. The carry-over decision localized at about 1.3% of the model, and matched correct-vs-correct position interfaces made the contrast cleaner: result length, prompt length, and all other answer digits stayed fixed while one local decision changed. The overflow / carry-into-thousands interface reached 95% counterfactual-patch accuracy from about 2% of MLP channels.
The full behavior still did not follow. A composed mask with 14,436 MLP channels recovered only 29.00%, and a grouped local mask with 18,694 channels recovered 29.20%. Teacher-forced prefixes, sequential interface tracing, carry-chain stratification, result-length stratification, adaptive split search, causal group ranking, and conflict-pruned masks all improved some diagnostic. None recovered full addition at compact scale. The failure moved from "maybe attribution cannot find arithmetic" to "local pieces exist, but the binding computation is diffuse in this representation."
Exp 4: Conditioning moved the frontier
The next hypothesis was representational. Addition might be sparse in a better coordinate system while remaining diffuse in the native one. We trained a rank-32 rsLoRA adapter (Kalajdzievski, 2023) over all linear modules with task loss plus KL to the base model, then swept merge scales and selected the lowest-KL scale that preserved target accuracy. In the main run, that scale was 0.55 with KL beta 0.05.
The extraction test stayed fixed. In the base representation, the compact composed mask kept 14,436 MLP channels and recovered 29.00%. After rank-32 KL conditioning, the comparable top-k mask kept 12,661 channels, about 5% of the MLP universe, and recovered 91.33% autoregressive exact accuracy. A later squeeze reduced the target-90 mask to 11,672 channels at 90.60% recovery and dropped whole layers from the mask. High-recovery mode still needed 58,619 channels for 99.53%, so conditioning moved the frontier without erasing the residual tail.
Exp 4 controls: Why the KL constraint mattered
Ordinary task LoRA did not explain the result. Rank-32 no-KL LoRA reached 49.53% at similar compact scale and needed 167,065 channels to approach the target-90 regime. Lower-rank KL ladders did not beat rank 32; the best lower-rank run was rank 8 at 170,259 channels for 90.47% generation recovery. Full-parameter SFT also needed a broad mask, reaching 90.80% only at 179,311 MLP channels.
The KL result was not a simple "the model stayed internally close" story. CKA (Kornblith et al., 2019) and top-10 subspace overlap show that the KL-conditioned representation moved farther from the base than the no-KL representation, while preserving behavior better. The control result is narrower and more useful: KL conditioning kept the behavior anchored while allowing the internal substrate to reorganize.
Exp 5: The SFT side branch and the ablation lesson
The SFT branch answered a different question. Per-digit-value circuits stayed diffuse in the base; below 25% of MLPs, no position exceeded 30% recovery on its own digit. This made the intervention choice more important. Mean ablation looked generous when means were computed on the addition evaluation set: k=10,000 gave 82.7% under mean ablation but 23.1% under zero ablation. That result made clear that replacements can leak task-shaped information into an intervention.
Supervised fine-tuning on 16,000 three-digit failure pairs lifted three-digit accuracy from 67.03% to 99.60%. It also generalized to adjacent arithmetic tasks in the notes: four-digit addition rose from 60% to 94%, two-digit multiplication from 62% to 90%, and two-digit addition from 92% to 100%. The qualitative errors changed too, with digit loops and decimal-like completions disappearing in examples. This branch supported the larger theme that conditioning changes what the model exposes, even when the conditioning objective is not the final low-rank KL recipe.
Exp 6: Concentration, not rank collapse
Mechanism audits tested whether conditioning simply made hidden states lower-dimensional. The rank audit ruled that out. Effective rank increased in many middle layers: the canonical audit reports mean effective rank of 9.878 for base, 11.789 for rank-32 KL, and 10.183 for no-KL. The more relevant change was where task-relevant activity landed. Mask-energy share rose from 0.329 in the base to 0.462 under rank-32 KL, meaning the recovered mask carried a larger share of the task MLP activity.
The audits were stratified by layer, answer position, and carry regime because addition is not uniform across regimes. Causal low-rank projection gave another view: projected task directions helped, but the rank-128 top-k projections remained far below the sparse mask. The mask result therefore cannot be reduced to a generic low-dimensional projection story.
Exp 6 controls: Transfer and wrong tasks
The transfer matrix tested whether a mask learned in one model state worked in another. Masks from base, rank-32 KL, rank-32 no-KL, full-SFT KL, and full-SFT CE were evaluated across the corresponding models. The rank-32 KL sparse mask worked on the conditioned model and did not transfer cleanly to base or no-KL. Broad masks transferred more readily because they kept many more channels.
Wrong-task controls sharpened the claim. Format-only training, digit reversal, random labels, copy, and next-token KL alone did not produce a sparse arithmetic circuit. KL-only preserved arithmetic but its sparse top-k mask reached only 11.40%, and its target-level mask stayed broad. The effect is task-specific representation conditioning, not a generic property of KL-LoRA.
Exp 7: Boundary tests by carry regime
Regime routing tested whether the remaining errors were mainly a mask-selection problem. The global rank-32 KL top-k mask recovered 97.65% on one-carry examples, 93.83% on no-carry examples, 92.38% on fully cascading carries, and 88.62% on late multi-carry cases. Per-regime masks were tested under global, union, core/intersection, and same-budget routing. Same-budget routing reached 89.47%, below the 91.33% global mask; a broader union reached 93.20% by using more channels. The residual hard regimes appear to reflect computation difficulty, not only channel choice.
Exp 8: Cross-model replication
The same recipe on the non-math Qwen2.5-1.5B sibling preserved the direction of the result but widened the frontier. Rank-32 KL still beat no-KL, but it needed 114,026 channels for 90.07%, while no-KL needed 157,696 channels for 89.67%. The merged non-math adapter reached 95.83% exhaustive exact accuracy, below the math model setup. Pretraining and conditioning therefore interact: the non-math model benefits from conditioning, but the math model starts closer to a sparse arithmetic solution manifold.
Exp 9: Training sparse gates directly
L0 gated training tried to optimize the sparse mask rather than find it after the fact. Hard-concrete gates (Louizos et al., 2018) were placed per MLP channel on top of the frozen base plus the rank-32 KL adapter, with donor patching during the forward pass. The run exposed three practical failure modes: stochastic gates during training did not match deterministic evaluation, closed gates tended to stay closed during the sparsity ramp, and the lambda window between no sparsity and behavior collapse was narrow. The gated runs produced frontier points, but did not materially beat the post-hoc 11,672-channel, 90.60% result.
Exp 10: Pre-allocating the circuit
Slot LoRA asked for a stronger form of evidence. Instead of choosing channels after training, it committed a set of MLP channel slots before training and constrained LoRA updates to weights touching those slots. A seeded 12,661-channel slot replicated the post-hoc result slightly more cleanly. An 8,000-channel slot had a small drop, 5,000 began to break, and 3,000 or 1,500 broke. Even at a similar channel count, pre-allocation reduces the risk that localization is only a retrospective selection effect.
What the chronology establishes
Across these experiments, recovery always means constrained-model task accuracy, not a separate proxy score. Teacher-forced and autoregressive recovery remain separate, with 91.33% reported in the harder autoregressive mode. The experimental path itself is part of the argument. The project began with a simple question about whether attribution could find arithmetic signals. It ended with a sharper claim: the base model carries the behavior, local pieces are recoverable, composition fails, and low-rank KL conditioning can make the full behavior compactly extractable under the same recovery test.